从零构建大模型(一)
理解大语言模型
什么是大语言模型(LLM)
大语言模型是一种用于理解、生成和响应类似人类语言文本的神经网络。其主要特征:
- 深度神经网络
- 大规模文本数据训练
由于大语言模型(LLM)能够生成文本,因此也被称为生成式人工智能(GenAI、Generative Artificial Intelligence)
大语言模型是深度学习技术的具体应用,深度学习是机器学习的一个分支,主要使用多层神经网络
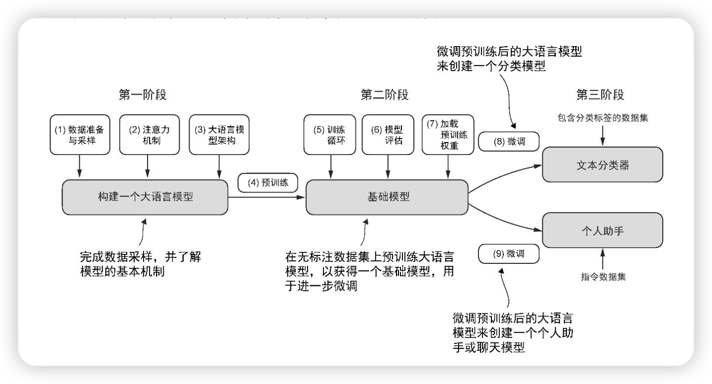
大语言模型的构建阶段
大语言模型的构建通常包括预训练(pre-training)和微调(fine-tuning)。预训练是在大规模、多样化的数据集上进行的(网络资料、图书、研究论文等),目的是让大模型形成全面 的语言理解能力。
微调阶段会在规模较小的特定任务或领域数据集上对模型进行针对性训练,目的是进一步提升其特定能力(例如:代码生成能力、分类、文本总结、翻译等)。
大模型的微调是在标注数据集上进行训练,从而得到特定的能力。微调大模型最流行的两种方法:
- 指令微调
- 分类任务微调
人自出生之日便开始了预训练,自上学之后,便开启了微调。
Transformer 架构
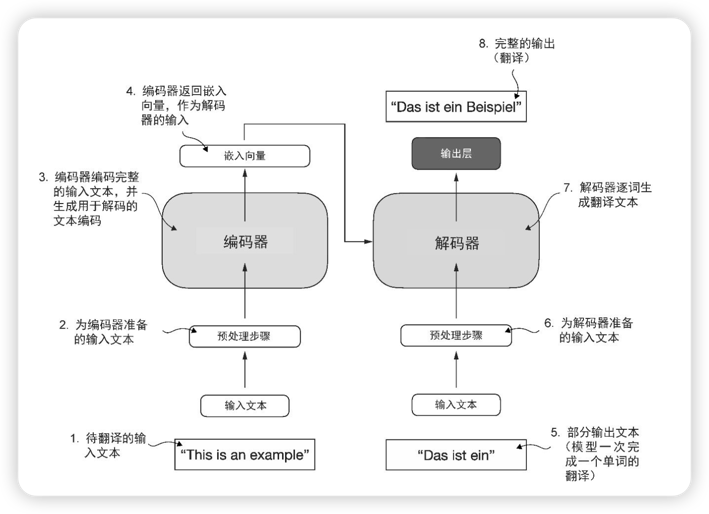
Transformer 架构由两个子模块构成:
- 编码器:负责处理输入文本,将文本编码为一系列数值表示或向量,以捕捉上下文信息。上下文信息的捕捉动作,是自注意力机制(self-attention mechanism)实现的。
- 解码器:负责接收这些编码向量,并据此生成输出文本。
构建大语言模型路线图