从零构建大模型(二)
处理文本数据
理解词嵌入
深度神经网络模型无法直接处理原始文本,因为文本数据是离散的,所以无法直接进行神经网络所需的数学运算。这样就需要一种将 文本(单词)表示为连续值的向量格式的方法。
将数据转换为向量格式的过程通常称为嵌入(embeding)。这里需要注意:不同的数据格式需要使用不同的嵌入模型。为文本设计的嵌入 模型并不适用于嵌入音频数据或视频数据。
(为什么不能直接根据文本编码规范、视频编码规范、音频编码规范做出一个中间表示层呢?)
嵌入的本质是从离散到连续向量空间中的点。词嵌入主要是对数据进行不同维度上的分类。维度可以从一维到数千维不等。维度越高 捕获的关系更细微,但计算效率会变低。
大语言模型准备嵌入向量的过程,包括将文本分割为单词、将单词转换为词元,以及将词元转化为嵌入向量。
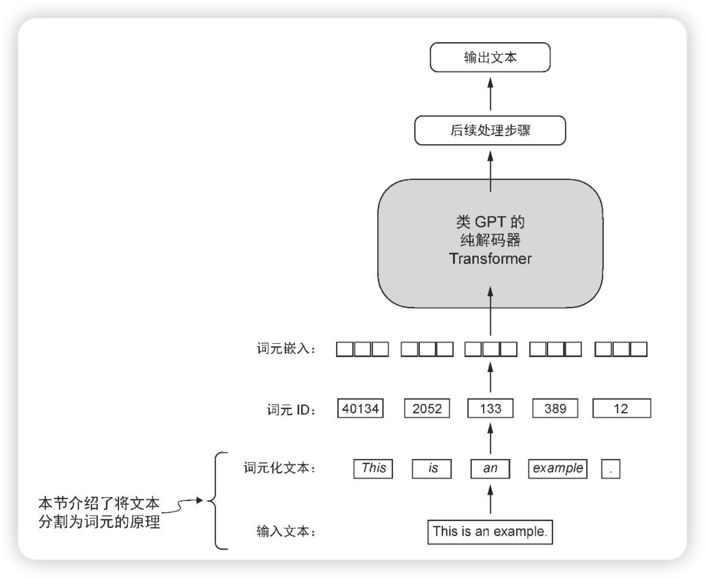
分词以及词元
分词是将文本处理为单个词,并去掉重复的词。之后按照字母表顺序排序。 将排序后的词转换为词元 ID,即每个词生成唯一的数字表示。
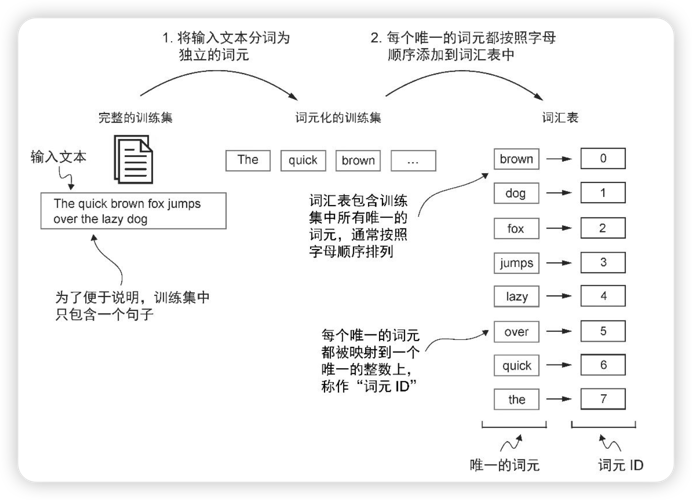
当前的词元是在有限集上进行构建的,所以当超过有限集之后,会出现异常情况。 为了兼容超限的情况,引入了特殊上下文词元。
引入特殊上下词元
此书中作者引入了 <|unk|> 和 <|endoftext|>:
1. <|unk|> 用于表示超过词元集合的词
2. <|endoftext|>用于表示多个文本之间的关系,例如两个文档之间的关系。
虽然引入了表示超过词元集合的特殊词元,但在分词器中的实现,并不能将词还原,例如:将 Hello 编码后得到 <|unk|>,但在还原的时候,会出现错误。
为了能覆盖未知的文本,出现了更进一步的分词算法:BPE。
BPE 会将不在词元集合中的词,进一步的按照字母或子词进行拆分。这样便可以还原。
滑动窗口进行数据采样
数据采样是构建:输入-目标对。高效的数据采样实现中,滑动窗口是核心算法之一。
输入-目标对需要使用 Pytorch 张量的形式表示,对于此书中需要使用两个张量: 1. 输入词元张量 2. 目标词元(预测的目标词元)张量
创建词元嵌入
神经网络反向传播算法?
由于嵌入层只是独热编码和矩阵乘法方法的一种高效的实现,因此它可以被视为一个能够通过反向传播进行优化的神经网络层。
词元嵌入层使用输入-目标张量创建模型可以理解的数据。词元嵌入层是将离散的符号转换为模型可以处理的连续数学表示。
嵌入层的工作机制是,无论词元 ID 在输入序列中的位置如何,相同的词元 ID 始终被映射到相同的向量表示。
编码单词位置信息
原则上,带有确定性且与位置无关的词元ID嵌入能够提升其可再现性。然而,由于大语言模型的自注意力机制本质上与位置无关,因此向模型中注入额外的位置信息是有帮助的
位置嵌入的目的是:提升大语言模型对词元顺序及其相互关系的理解能力。从而实现更准确、更具上下文感知力的预测。