从零构建大模型(四)
从头实现GPT模型进行文本生成
Transformer 块包含如下部分:
- 层归一化
- GELU 激活函数
- 前馈神经网络
- 快接连接
层归一化
层归一化的主要思想是调整神经网络层的激活(输出),使其均值为0且方差(单位方差)为1。这种调整有助于加速权重的有效收敛,并确保训练过程的一致性和可靠性。
层归一化通常在多头注意力模块的前后进行,同时层归一化还应用于最终输出层之前。
均值和方差的计算方法:

样本特征:x = [2, 4, 6, 8] (d=4)
设:ε = 0.00001, γ = [1,1,1,1], β = [0,0,0,0]
层归一化是在特征维度上进行归一化。层归一化是对每个输入独立进行归一化,不受批次大小的限制,因此更灵活和稳定。在资源受限的环境中部署模型时尤为重要。
GELU 激活函数
GELU 激活函数更为复杂且平滑,结合了高斯分布和sigmoid门控线单元,能提升深度学习模型的性能。
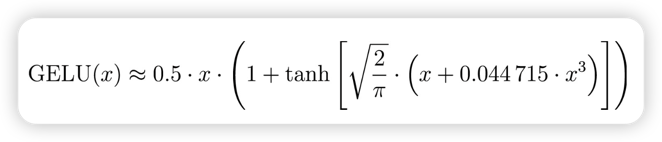
GELU 的平滑特性可以在训练过程中带来更好的优化效果,因为它允许模型参数进行更细微的调整。
书中 FeedForward 模块是一个小型神经网络(前馈神经网络),有两个线性层和一个 GELU 激活函数组成。
第一个线性层用来扩展可表示的空间,第二个线性层用来缩放到原始大小。输入和输出维度的一致性简化了架构,在后续堆叠多个层时无须调整维度,这样可以增强扩展能力。
快捷连接
快接连接的目的是避免梯度消失,在训练过程中,梯度反向传播时逐渐变小,导致网络层难以有效训练。快捷连接通过跳过一个或多个层,为梯度在网络中的流动提供了一条可替代且更短的路径。
文本生成的过程
- 将文本输入编码为词元 ID
- GPT 模型返回一个由向量组成的矩阵,其中每个向量有 50257 维度
- 提取最后一个向量,它对应于 GPT 模型应该生成的下一个词元
- 使用 softmax 函数将 logits 转换为概率分布
- 确定最大值的索引,该位置代表词元 ID
- 将词元追加到上一轮输入中,进行下一轮输入
- 如果最大的元素位于第 257 位,那么我们就得到了词元 ID 257